
编者按:下个月,谷歌旗下的DeepMind公司研发的人工智能“阿尔法围棋”,将与李世石进行百万美金的人机大战。人工智能也被中国科技界视为实现弯道超车的一次难得的历史机遇, 看好人工智能这一未来最重要的产业方向。问题是,计算机深度学习有多深,学了究竟有几分?
(1)
2016 年一月底,人工智能的研究领域,发生了两件大事。
先是一月二十四号,MIT 的教授,人工智能研究的先驱者,Marvin Minsky 去世,享年89岁。

三天之后,谷歌在自然杂志上正式公开发表论文,宣布其以深度学习技术为基础的电脑程序 AlphaGo, 在2015年十月,连续五局击败欧洲冠军,职业二段樊辉。
这是第一次机器击败职业围棋选手。 距离97年IBM电脑击败国际象棋世界冠军,一晃近二十年了。
极具讽刺意义的是, Minsky 教授,一直不看好深度学习的概念。 他曾在1969年出版了 Perceptron (感知器) 一书,指出了神经网络技术 (就是深度学习的前身)的局限性。 这本书直接导致了神经网络研究的将近二十年的长期低潮。
神经网络研究的历史,是怎样的?
深度学习有多深? 学了究竟有几分?
(2)
人工智能研究的方向之一, 是以所谓 "专家系统" 为代表的, 用大量 "如果-就" (If - Then) 规则定义的, 自上而下的思路。
人工神经网络 ( Artifical Neural Network),标志着另外一种,自下而上的思路。
神经网络没有一个严格的正式定义。 它的基本特点, 是试图模仿大脑的神经元之间传递,处理信息的模式。
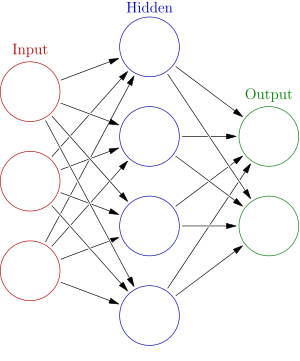
一个计算模型,要划分为神经网络,通常需要大量彼此连接的节点 (也称 '神经元'),并且具备两个特性:
1。每个神经元, 通过某种特定的输出函数 (也叫激励函数 activation function),计算处理来自其它相邻神经元的加权输入值。
2。神经元之间的信息传递的强度,用所谓加权值来定义,算法会不断自我学习,调整这个加权值。
在此基础上,神经网络的计算模型, 依靠大量的数据来训练, 还需要:
1。成本函数 (cost function):用来定量评估根据特定输入值, 计算出来的输出结果,离正确值有多远,结果有多靠谱。
2。学习的算法 ( learning algorithm ):这是根据成本函数的结果, 自学, 纠错, 最快地找到神经元之间最优化的加权值。
用小明,小红和隔壁老王们都可以听懂的语言来解释, 神经网络算法的核心就是:计算, 连接, 评估, 纠错, 疯狂培训
随着神经网络研究的不断变迁,其计算特点 ,和传统的生物神经元的连接模型渐渐脱钩。
但是它保留的精髓是: 非线性,分布式, 并行计算, 自适应, 自组织。
(3)
神经网络作为一个计算模型的理论,1943年最初由科学家 Warren McCulloch 和Walter Pitts 提出。
康内尔大学教授 Frank Rosenblatt 1957年提出的"感知器" (Perceptron),是第一个用算法来精确定义神经网络, 第一个具有自组织自学习能力的数学模型,是日后许多新的神经网络模型的始祖。
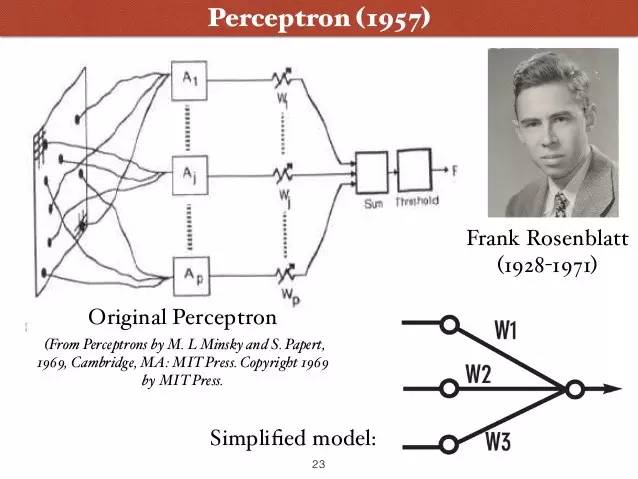
Rosenblatt 乐观地预测,感知器最终可以 "学习,做决定,翻译语言"。 感知器的技术,六十年代一度走红,美国海军曾出资支持这个技术的研究, 期望它 "以后可以自己走, 说话, 看, 读, 自我复制, 甚至拥有自我意识"。
Rosenblatt 和 Minsky 实际上是间隔一级的高中校友。但是六十年代, 两个人在感知器的问题上,展开了长时间的激辩。 Rosenblatt 认为感应器将无所不能, Minsky 则认为它应用有限。
1969 年, Marvin Minsky 和 Seymour Papert 出版了新书: "感知器: 计算几何简介"。 书中论证了感知器模型的两个关键问题:
第一, 单层的神经网络无法解决不可线性分割的问题, 典型例子如异或门, XOR Circuit ( 通俗地说, 异或门就是: 两个输入如果是异性恋,输出为一。 两个输入如果是同性恋,输出为零 )
第二, 更致命的问题是,当时的电脑完全没有能力完成神经网络模型所需要的超大的计算量。
此后的十几年,以神经网络为基础的人工智能研究进入低潮,相关项目长期无法得到政府经费支持,这段时间被称为业界的核冬天。
Rosenblatt 自己则没有见证日后神经网络研究的复兴。 1971年他43岁生日时,不幸在海上开船时因为事故而丧生。
二
(1)
1970年,当神经网络研究的第一个寒冬降临时,在英国的爱丁堡大学,一位二十三岁的年轻人, Geoffrey Hinton, 刚刚获得心理学的学士学位。

Hinton 六十年代还是中学生时,就对脑科学着迷。当时一个同学给他介绍关于大脑记忆的理论是:
大脑对于事物和概念的记忆, 不是存储在某个单一的地点,而是像全息照片一样, 分布式地, 存在于一个巨大的神经元的网络里。
分布式表征 (Distributed Representation), 是神经网络研究的一个核心思想。
它的意思是,当你表达一个概念的时候,不是用单个神经元,一对一地存储定义; 概念和神经元是多对多的关系: 一个概念可以用多个神经元共同定义表达, 同时一个神经元也可以参与多个不同概念的表达。
举个最简单的例子, 一辆 "大白卡车",如果分布式地表达,一个神经元代表大小,一个神经元代表颜色,第三个神经元代表车的类别。 三个神经元同时激活时,就可以准确描述我们要表达的物体。
分布式表征,和传统的 局部表征 (localized representation) 相比,存储效率高很多。 线性增加的神经元数目,可以表达指数级增加的大量不同概念。
分布式表征的另一个优点是,即使局部出现硬件故障,信息的表达不会受到根本性的破坏。
这个理念让 Hinton 顿悟, 使他四十多年来, 一直在神经网络研究的领域里坚持下来没有退缩。
本科毕业后, Hinton 选择继续在爱丁堡大学读研, 把人工智能作为自己的博士研究方向。
周围的一些朋友对此颇为不解。 "你疯了吗? 为什么浪费时间在这些东西上? 这 (神经网络)早就被证明是扯淡的东西了。"
Hinton 1978 年在爱丁堡获得博士学位后, 来到美国继续他的研究工作。
(2)
神经网络当年被 Minsky 诟病的问题之一是巨大的计算量。
简单说,传统的感知器用所谓 "梯度下降"的算法纠错时,耗费的计算量,和神经元数目的平方成正比。 当神经元数目增多,庞大的计算量,是当时的硬件无法胜任的。
1986年七月, Hinton 和 David Rumelhart 合作在自然杂志上发表论文, "Learning Representations by Back-propagating errors", 第一次系统简洁地阐述,反向传播算法在神经网络模型上的应用。
反向传播算法,把纠错的运算量, 下降到只和神经元数目本身成正比。
反向传播算法,通过在神经网络里增加一个所谓隐层 (hidden layer), 同时也解决了感知器无法解决异或门 (XOR gate) 的难题。
使用了反向传播算法的神经网络,在做诸如形状识别之类的简单工作时,效率比感知器大大提高。
八十年代末计算机的运行速度,也比二十年前高了几个数量级。
神经网络的研究开始复苏。
(3)
Yann Lecun (我给他取个中文名叫 "严乐春"吧) 1960年出生于巴黎。 1987年在法国获得博士学位后,他曾追随 Hinton 教授到多伦多大学做了一年博士后的工作, 随后搬到新泽西州的贝尔实验室继续研究工作。

在贝尔实验室,严乐春 1989年发表了论文, "反向传播算法在手写邮政编码上的应用"。他用美国邮政系统提供的近万个手写数字的样本来培训神经网络系统, 培训好的系统在独立的测试样本中, 错误率只有5%。
严乐春进一步运用一种叫做"卷积神经网络" (Convoluted Neural Networks) 的技术,开发出商业软件,用于读取银行支票上的手写数字, 这个支票识别系统在九十年代末,占据了美国接近20%的市场。
此时就在贝尔实验室, 严乐春临近办公室的一个同事的工作,又把神经网络的研究带入第二个寒冬。
(4)
Vladmir Vapnik, 1936年出生于前苏联, 90年移民到美国,在贝尔实验室做研究。

早在1963年, Vapnik 就提出了 支持向量机 (Support Vector Machine) 的算法。支持向量机, 是一种精巧的分类算法。
除了基本的线性分类外,在数据样本线性不可分的时候, SVM 使用所谓 "核机制" (kernel trick) 的非线性映射算法, 将线性不可分的样本转化到高维特征空间 (high-dimensional feature space),使其线性可分。
SVM, 作为一种分类算法,九十年代初开始, 在图像和语音识别上,找到了广泛的用途。
在贝尔实验室的走廊上,严乐春和 Vapnik 常常就(深度)神经网络和 SVM,两种技术的优缺点,展开热烈的讨论。
Vapnik 的观点是, SVM,非常精巧地在 "容量调节" (Capacity Control)上 选择一个合适的平衡点, 而这是神经网络不擅长的。
什么是 "容量调节"? 举个简单的例子: 如果算法容量太大,就像一个记忆力极为精准的植物学家, 当她看到一颗新的树的时候,由于这棵树的叶子和她以前看到的树的叶子数目不一样,所以她判断这不是树; 如果算法容量太小,就像一个懒惰的植物学家,只要看到绿色的东西,都把它叫做树。
严乐春的观点是, 用有限的计算能力,解决高度复杂的问题,比"容量调节"更重要。 支持向量机,虽然算法精巧,但本质就是一个双层神经网络系统。它的最大的局限性,在于其"核机制"的选择。 当图像识别技术需要忽略一些噪音信号时,卷积神经网络的技术,计算效率就比 SVM 高的多。
在手写邮政编码的识别问题上, SVM 的技术不断进步,1998年就把错误率降到低于 0.8%,2002年最低达到了 0.56%, 这远远超越同期传统神经网络算法的表现。
神经网络的计算,在实践中还有另外两个主要问题:
第一, 算法经常停止于局部最优解,而不是全球最优解。 这好比"只见树木,不见森林"。
第二, 算法的培训,时间过长时,会出现过度拟合 (overfit),把噪音当做有效信号。
(未完待续)
作者简介:王川,投资人,中科大少年班校友,现居加州硅谷。个人微信号9935070,公众号 investguru ,新浪微博是“硅谷王川",知乎专栏 "兵无常势", 财新网博客 wangchuan.blog.caixin.com, 文章表达个人观点仅供参考,不构成对所述资产投资建议,投资有风险,入市须谨慎。

相关阅读:
 图片
图片








