①这个指数级增长的算力需求,过去主要靠英伟达的GPU来扛。国内量子计算公司要做国产化适配,绕不开这道坎; ②已经落地生物医药、金融、航天等场景。
《科创板日报》5月25日讯(记者 李明明)走进图灵量子企业,最先闯入视线的是量子智算中心,由TuringQ光量子计算机和经典服务器组成的一排排机柜发出发出低沉均匀的嗡鸣,像某种精密仪器特有的呼吸。
智算中心屏幕上数据不断变化,实验室里工程师电脑上不断迭代更新密密麻麻的数据。这里不像想象中的尖端实验室那样一尘不染、冰冷遥远,倒更像一个埋头赶路的工程现场。
“我们在做的是让中国的量子计算,从芯片到算法,真正跑在中国的算力上。这是一条完整的链路,缺任何一环都不行。”
实地探访时,图灵量子算法总监赵翔把这句话对《科创板日报》记者重复了两遍。语气不算激昂,但在整个采访中,这句话的分量一点点沉下去。
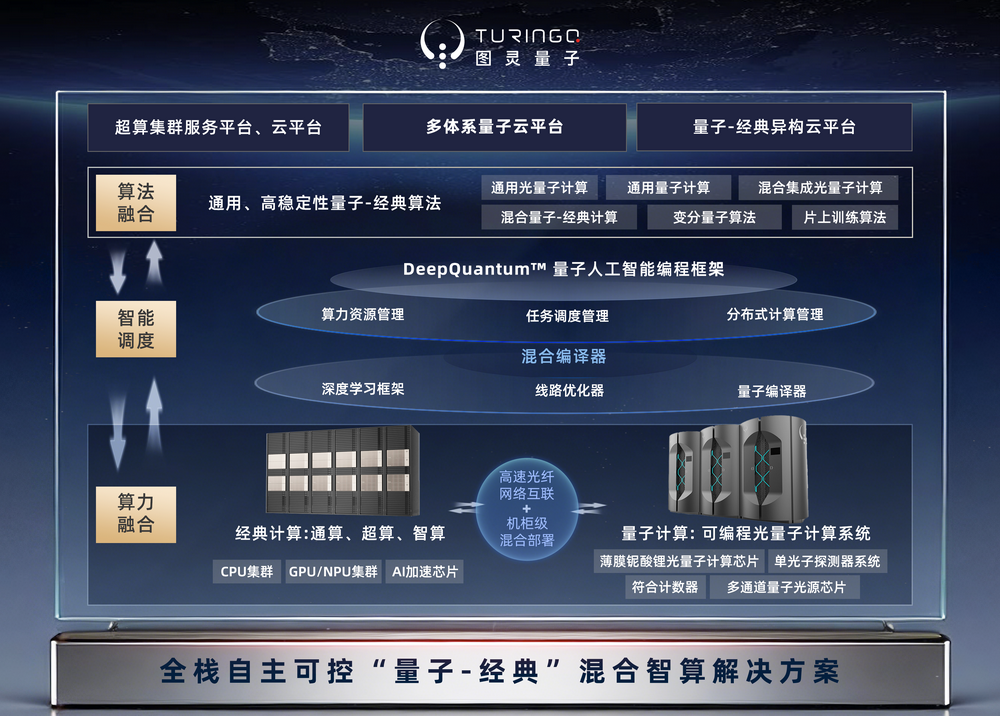
近日,图灵量子宣布完成国内首个光量子计算软硬件与国产GPU、国产操作系统的全栈适配验证。这意味着,从光量子算法开发、国产GPU加速仿真、云平台统一调度,到光量子计算机真机运行——这条完整的国产化工程闭环,全栈跑通了。

国产GPU跑通量子仿真 最高加速62.1倍
赵翔作为技术出身,说话习惯拆解。当被《科创板日报》记者问及“全栈国产化”到底什么意思,他没有直接抛概念,而是从最底层的硬件开始数:光源、芯片、探测器、整机、编程框架、云平台……一路数到最上层的行业应用。
“硬件上,从光源到芯片到探测器,我们都做到了全国产。软件上,我们的编程框架DeepQuantum、量擎云平台,也都是自研的。”他表示,“这次最关键的一步,是把DeepQuantum跟国产GPU做了深度适配。”
为什么这步最关键?
因为在量子计算工程化落地的现实里,大部分工作其实还离不开经典算力。尤其是在NISQ(含噪中等规模量子)阶段,量子比特数量有限、噪声控制还不完美,开发者需要先在经典计算机上仿真、验证、调优量子算法,跑通了再上真机。这个环节,GPU是绝对主力。此前,国内量子企业的算法仿真几乎全部依赖英伟达GPU,一旦供应链出现波动,整个研发链条都会停摆。这成为量子计算自主可控的最大短板之一。
“量子计算说到底是一个指数级增长的计算模型。”赵翔打了个比方,“模拟30个量子比特,需要约10亿个复数存在显存里。31个比特,复数量就要翻到20亿。你每加一个比特,需要的GPU资源就翻一倍。”
这个指数级增长的算力需求,过去主要靠英伟达的GPU来扛。国内量子计算公司要做国产化适配,绕不开这道坎。
图灵量子这次选了多家主流GPU厂商,包含海光、摩尔线程、沐曦,还有壁仞科技。
“我们不是简单跑通一个Demo,是要让开发者能在国产GPU环境里,完整地完成量子算法的开发、仿真、调优、验证这一整条工作流。”赵翔说。
测试结果给了底气。在双GPU分布式后端上,量子傅里叶变换任务相对于CPU的最高加速比达到了62.1倍。四类典型基准算法——GHZ态制备、量子态采样、量子傅里叶变换、变分梯度计算——全部稳定扩展到30量子比特。最大绝对误差控制在1.19e-06以内。DeepQuantum在国产GPU环境中连续跑了48小时,系统稳定。
“这意味着,DeepQuantum已经具备在国产GPU环境中支撑典型量子算法研发、仿真和验证的工程化能力。”赵翔认为。
壁仞科技技术负责人也对《科创板日报》记者表示,基于壁仞 SUPA 软件栈在量子计算场景下的持续完善,壁仞 GPU 已具备复数运算与复杂量子线路模拟等关键能力。在和图灵量子的双方联合验证中,相关能力不仅顺利通过了DeepQuantum基础测试用例,更成功支撑高复杂度 Shor 算法模拟运行。
赵翔表示,“未来的容错量子计算,一定需要大量的经典算力来做实时纠错。经典 GPU 承担着仿真、优化、调度和纠错等关键环节,相当于系统的另一半底座。”
这也是是英伟达积极布局量子计算的原因:它要让自己成为量子计算时代不可或缺的底座。而凭借其在GPU市场的统治地位,英伟达已经在事实上大大加快了国外量子厂商与CUDA生态的适配速度。
“目前国内还没有一个GPU公司能像英伟达那样一家独大、制定标准。”赵翔说,“所以我们选择跟多家国产GPU厂商合作,希望大家能一起形成一套统一的框架或标准,让GPU和QPU的融合变得更开放、更高效。如果GPU这一侧仍由国外公司提供,整个量超融合基础设施就难以真正自主可控。”
落地在哪里?生物医药、金融、航天,但不是大模型
对当下最热的量子计算加速AI大模型话题,赵翔表示,“大模型参数上万亿,数据量太大。量子计算机更擅长解决小数据但极难的问题——比如给你一个很大的整数,找到它的两个质因数。问题描述可能就几十个字,但算起来可能要很久。”
赵翔表示,目前量子计算最切实两个应用场景,是生物医药和化学材料。
“这两个行业的提升是可见的、明显的,而且是快速迭代发展的那种。”赵翔举例说,IBM最近实现了大约13000个原子的求解,核心思路就是用量子计算机先对问题空间进行采样,把解空间缩小到符合物理约束的小空间,再交给经典GPU集群去算。“没有量子计算机做方向性指引,经典算力在大规模解空间里会迷失方向。”
据悉,图灵量子已经在跟远大、博望等药企合作,用这套量超融合架构做新药分子设计和蛋白质结构计算。在金融领域,组合优化、风险控制、投资策略优化也有落地。
“这些场景的共同特点是:问题解空间巨大,但问题本身描述很短,这是量子计算机的舒适区。”
此外,在热门的航天领域,图灵量子与产业链中的光通信赛道企业蓝星光域、极光星通在激光通信领域,调制器和窄线宽激光器及模块产品开展合作;此前,其与北京航空航天大学合作的星载SAR光计算项目顺利完成验收并实现交付。
全栈国产化闭环打通之后,图灵量子下一步要做什么?
赵翔表示,图灵量子的下一步很清晰:一边推动量子计算机本身的硬件迭代——降低错误率、扩大规模、实现多机柜互联;一边加快量超融合智算中心的全国部署。
去年末,图灵量子已与摩尔线程签署战略合作,共同打造“QPU+GPU”异构计算平台。又在今年3月,与科华数据达成合作,推进量超融合智算中心部署。
这些动作串起来,一条从技术适配到商业部署的路径,已经清晰可见。
“我们的核心目标就两个:让量子计算机能在现有的AI智算中心里大量部署;部署完之后,能产生真实的经济收益,服务更多行业。”赵翔说。









