①高通采用专用近内存计算方案,选择将专用近内存加速器堆叠在LPDDR存储堆栈下方; ②完整加速器级别下,HBC单位功耗带宽是HBM的6倍;单位功耗存储容量是静态存储SRAM的200倍; ③微软Azure已确认将部署高通的HBC芯片。
《科创板日报》6月25日讯(编辑 宋子乔) 当地时间6月25日,在2026投资者日上,高通正式发布面向AI数据中心市场的突破性技术——高带宽计算架构(HBC,High-Bandwidth Compute),旨在打破存储墙瓶颈,大幅提升内存容量和带宽。
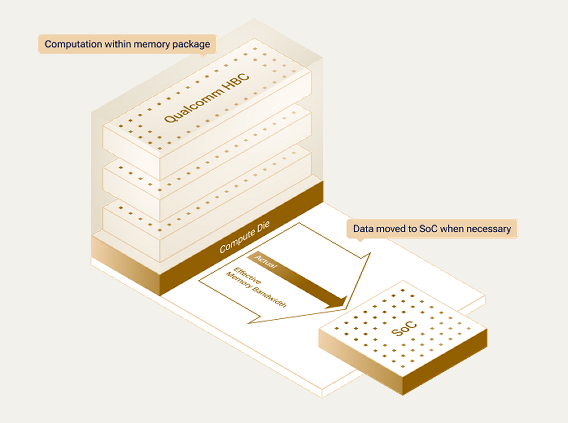
此HBC架构采用专用近内存计算方案,将计算单元直接置于DRAM底层。
具体来看,高通以硅通孔(TSV)工艺实现3D堆叠芯片设计,将专用近内存加速器堆叠在LPDDR存储堆栈下方。
LPDDR是DRAM下专为低功耗设备设计的分支,核心原生优势为超低功耗,同时具备易3D堆叠、单卡内存容量上限更高、性价比高的特点。它原本多用于手机、边缘终端,近年逐步渗透到AI推理类数据中心加速卡场景。高通选择LPDDR作为存储介质的主要原因在于其单堆容量更大。
据高通公布的数据,完整加速器级别下,HBC单位功耗带宽是HBM的6倍(意味着同等耗电下HBC的数据传输能力是HBM的6倍);单位功耗存储容量是静态存储SRAM的200倍(意味着同等耗电下,HBC能承载的存储容量是SRAM的200倍)。


高通同时公布了HBC技术路线图,并预测2029财年全球AI加速器市场规模将达6800亿美元。

第一代HBC Gen1将搭载于AI250加速器,预计2027年年中启动商业化样品测试,搭载HBC Gen1的AI250加速器单卡内存读写速率达133TB/s,有效带宽是采用标准LPDDR5X的AI200的18倍。
第二代HBC Gen2将配套AI300加速器于2028年推出。AI300与AI200相比,有效带宽最高可提升54倍,每瓦带宽比HBM提升7倍。
高通表示,全新HBC架构可实现更低的单位Token能耗、更高的有效存储带宽,同时降低系统总体拥有成本。该架构依托四大核心技术根基打造:领先的3D集成工艺、全系统级协同设计、成熟的LPDDR技术积淀、顶尖功耗优化能力。
微软Azure已确认将部署高通的HBC芯片,HBC是高通Dragonfly数据中心解决方案的核心技术支柱之一。
当前,HBM是AI算力加速器的主流存储方案,但HBM不仅产能紧缺、单价高昂,还存在多项性能短板,如能耗高、单堆栈容量仅32-64GB、数据传输存在延迟,且只能集成在GPU侧边。
为此,高通与闪迪均有意破局,两公司目前的核心思路有异曲同工之妙,即采用3D堆叠近内存计算,通过缩短存算间距改善存储墙问题。
但两者选择的存储介质不同,高通HBC以LPDDR DRAM为载体,存储叠在计算上方,目标直接替代HBM做云端AI推理,已有明确量产计划;闪迪最近公布的3D堆叠新专利则采用上层算力芯片、下层NAND闪存的结构,搭配原有HBM做大容量冷数据扩容,且仅停留在专利阶段。









